User Study
From Yesnt: Are Diffusion Relighting Models Ready for Capture Stage Compositing?
A Hybrid Alternative to Bridge the Gap
Relighting Accuracy
We conducted a user study to support improved perceived visual realism in comparison to the relighted proxy mesh using Blender (reference), serving as a conventional renderer-based baseline. A total of 55 participants were shown side-by-side still-image renderings of the same scene under identical target illumination, produced by two different relighting approaches: our method and the reference. Participants rated each pair according to two criteria: person realism (how realistic the human/foreground subject looks) and overall preference (which result they prefer overall) on a 7-point Likert scale.

Example of a still-image comparison in the user study.
Analysis
We analyze responses on a signed ±3 scale (positive indicates preference for our method) with participant-level aggregation. We report the mean score M, 95% bootstrap confidence intervals (CI) over participants, one-sided one-sample t-test p-values (H1: M > 0), Wilcoxon signed-rank p-values as a non-parametric robustness check, and Cohen's d effect sizes relative to zero. Table 1 summarizes the results for still-image comparisons. Participants significantly preferred our method in terms of perceived person realism and overall preference.
| Criterion | M | 95% CI | p (t-test) | p (Wilcoxon) | Cohen's d |
|---|---|---|---|---|---|
| Person realism | 0.63 | [0.32, 0.92] | < 10−5 | 1.53 × 10−4 | 0.53 |
| Overall preference | 0.43 | [0.12, 0.73] | 0.004 | 0.005 | 0.35 |
Table 1. User study results on still images. Positive M indicates preference for our method.
Temporal Consistency
Evaluation Protocol
Since we want to assess relighting quality across the most widely used paradigms, we include methods regardless of whether they guarantee frame-to-frame consistency for that purpose. We compare methods for single-frame relighting (Neural Gaffer, IC-Light), video diffusion (NVIDIA Diffusion Renderer), and 3D relightable scene representations (R3DG). Since these classes enforce temporal behavior in fundamentally different ways, temporal metrics are most informative when diagnosing per-frame methods (where temporal coherence is not guaranteed) and video diffusion (where temporal coupling is an explicit design goal).
For R3DG, temporal coherence largely follows from their temporally consistent 3D representation, we therefore do not treat temporal instability as their primary failure mode, given their subpar relighting quality.
Existing temporal consistency metrics such as TLPIPS or tPSNR primarily capture frame-to-frame differences and are poorly aligned with human perception of flickering over longer sequences. We therefore use them only for controlled ablations of our own method, and rely on a dedicated user study for perceptual comparisons.
User Study
For temporal evaluation, the 55 participants in the user study compared video sequences generated by our method and the NVIDIA Diffusion Renderer. Participants evaluated the results on three criteria: temporal smoothness (absence of flickering), person realism, and lighting realism (believability and consistency of illumination), using a 7-point Likert scale.
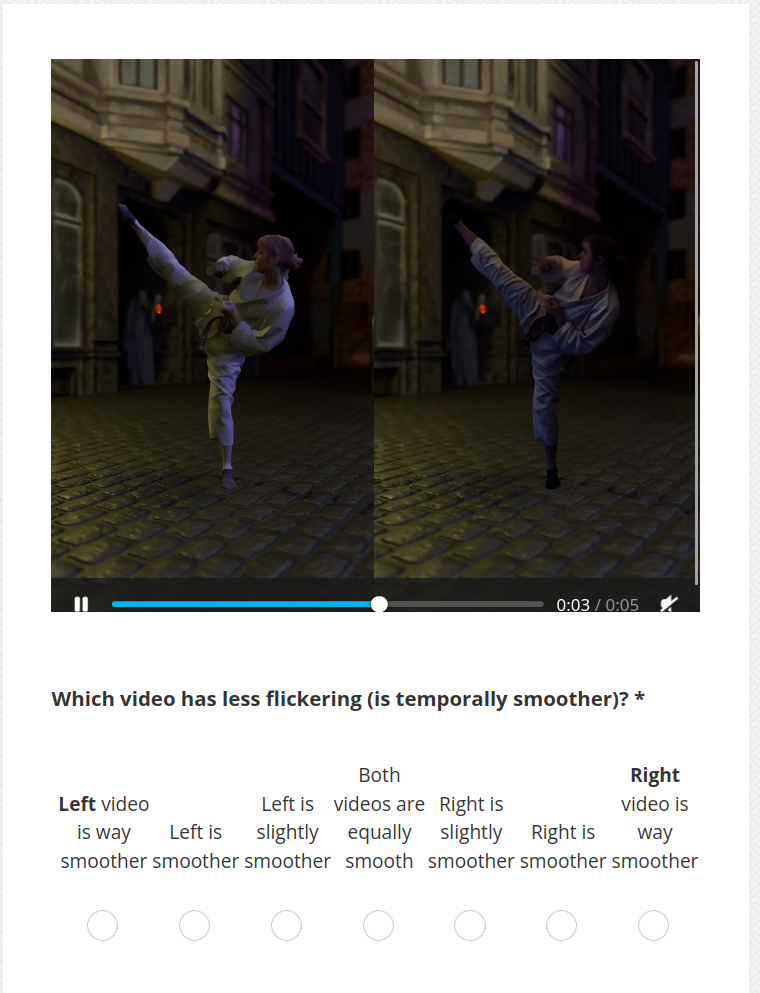
Example of a video comparison in the user study.
Analysis
We follow the same analysis protocol as in Sec. "Relighting Accuracy"; Table 2 reports results for video comparisons. Participants rated our method as substantially more temporally smooth (less flickering), with large effects. Person realism and lighting realism were also rated significantly higher for our method.
| Criterion | M | 95% CI | p (t-test) | p (Wilcoxon) | Cohen's d |
|---|---|---|---|---|---|
| Temporal smoothness (flicker) | 1.60 | [1.32, 1.85] | < 10−16 | 1.70 × 10−9 | 1.57 |
| Person realism | 1.20 | [0.94, 1.46] | < 10−12 | 7.75 × 10−9 | 1.20 |
| Lighting realism | 0.78 | [0.53, 1.02] | < 10−8 | 2.59 × 10−7 | 0.83 |
Table 2. User study results on videos. Positive M indicates preference for our method.