
Robot Learning
A formula sheet for the lecture
In the Robot Learning module, we explored how robots can use machine learning to tackle complex tasks. We began by working through Sutton and Barto’s book Reinforcement Learning: An Introduction, which provides a thorough introduction to the concepts and algorithms of reinforcement learning and is considered a standard reference in the field. I found it both engaging and accessible, even though I had little prior knowledge of the subject at the time.
The lectures also covered topics such as function approximation,transfer and meta-learning, inverse reinforcement learning, and kinematic models. For the exercises, we had to implement various algorithms in Python and solve tasks in the OpenAI Gym environment.
For the exam, however, the main focus was on understanding and applying the mathematical foundations and formulas from the book and lectures. To prepare, I created a formula sheet that summarized the key concepts and equations.
Robot Learning Formula Sheet
Fundamentals
Elements of a Reinforcement Learning System
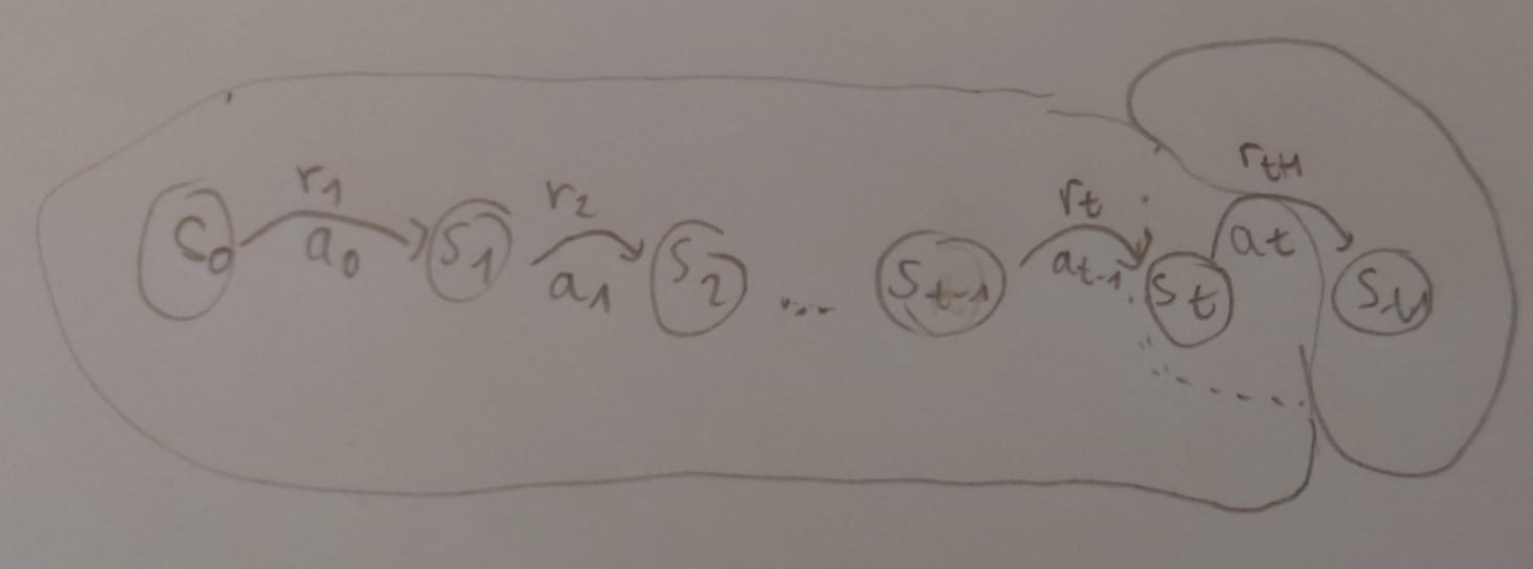
In Reinforcement Learning, an agent interacts with an environment in discrete time steps. At each time step t, the agent receives a state from the environment and selects an action based on its policy . The environment then transitions to a new state and provides a reward to the agent.
Markov Property
The Markov Property states that the future is independent of the past given the present. In Reinforcement Learning, this means the next state and reward depend only on the current state and action, not on the sequence of events that preceded it.
Since the indices in the formula above can be confusing, we can visualize the sequence of states and actions in question like this:
Return
The return at a point t of a trajectory is the sum of the discounted future rewards
RL Agent goal
The goal of a Reinforcement Learning agent is to find a policy that maximizes the expected return from the start state .
Bellman Equations
The Bellman Equations are fundamental recursive relationships in Reinforcement Learning that relate the value of a state (or state-action pair) to the values of its successor states (or state-action pairs). They are used to compute value functions and are the basis for many RL algorithms.
The Bellman Equation
The Bellman Equation expresses that instead of calculating the discounted cumulative reward by summing up all future rewards, we can decompose it into the immediate reward plus the discounted value of the next state.
State-Value function via Bellman Equation
The value of a state is the average return that can be acquired after that state when following a specific policy:
Action-value function via Bellman Equation
Bellman Principle of Optimality
The Bellman principle of optimality states that any part of an optimal policy must itself be optimal for the subproblem starting from that point.
Therefore, the value of a state under an optimal policy, must equal the expected return for the best action from that state. Because subproblems of an optimal solution are themselves optimal: Selecting the next action is a subproblem, so we need to select the optimal action there too.
If a policy is optimal, the remaining decisions must also be optimal
Bellman Optimality Equation For V
Bellman Optimality Equation For Q
Dynamic Programming Methods
Dynamic Programming methods are used to solve Markov Decision Processes (MDPs) when the model of the environment is known. They rely on the Bellman equations to iteratively compute value functions and improve policies.
Iterative Policy Evaluation
Use Bellman Equation for V to iteratively evaluate a policy.
Policy Improvement Theorem
If the one-step lookahead using policy is better than or equal to the value of the current policy , is at least as good as .
If for two deterministic policies and it holds that
then is at least as good as .
Policy Iteration
Evaluation step:
Improvement step:
Value Iteration
Computing the optimal policy
Given the optimal value function, we can compute the optimal policy.
Optimal Policy given V
Take the action with the highest value for the current state.
Optimal Policy given Q
Temporal Difference Learning
TD() update
with
where
- make all terms sum to one
- weight the returns:
- only the 1-step return survives: , for all others
- : full episode, monte carlo
Eligibility Traces in backward view
Eligibility traces assign credit to recently visited states. In the backward view, all states are updated with the current TD error, weighted by their eligibility trace.
The eligibility trace decays and is updated like this:
In the backward view of TD(), the value function is updated for all states:
TD(0) update
When , we only consider the one-step return. This is called TD(0) or one-step TD.
Monte Carlo Update rule
For , where n(s) is the number of times state s has been visited, this is the sample average method (an action-value method mentioned in the beginning of the lecture).
TD Control Methods
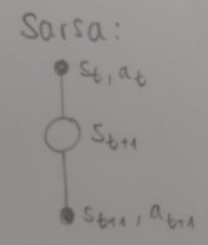
Sarsa
Sarsa is a temporal difference learning method that uses action values. We update them using the one-step TD target, so updates can be performed incrementally and not only after the episode is finished.
In practice, eligibility traces are used to weigh the influence of the current transition on all past states and decay over time. With them, we can have incremental updates not only to the preceding states but all states.
Sarsa()
Extends SARSA by introducing eligibility traces to speed up learning.
Q-Learning
off-policy, a TD- method that learns Q-values. learns as if we always will choose the optimal action (target policy) but actually still explores with epsilon-greedy (behaviour policy). Might learn an unsafe policy compared to Sarsa.
Policy Gradient Methods
REINFORCE
Instead of learning value functions, we directly learn a parameterized policy that selects actions. Use gradient ascent to optimize the policy parameters to maximize the expected return.
Example for Policy Gradient Policy
or softmax!
Actor-Critic Methods
REINFORCE has high variance because it uses the full return as an estimate of the action value. Actor-Critic methods reduce this variance by using a learned value function as a baseline.
- The actor represents the policy and is updated via a gradient step, like in REINFORCE.
- The critic represents the value or action value function and provides feedback to the actor, e.g. the td error or advantage estimate. It is updated using TD learning.
Improvements for Policy Gradient Methods
- Introduce a baseline to reduce variance (e.g. the value function)
- Proximal Policy Optimization (PPO): Limit the size of policy updates to ensure stable learning.
- use the probability ratio between the new policy and the old policy instead of
Linear Methods
LQR
LQR reward function
Maximize
where
- penalize being far from desired state
- penalize large actions
Optimal LQR policy
where
Linearizing a function
Given function
We can linearize it with
To get back to the and matrices:
=> Pull into the state by adding a dimension
Differential Dynamic Programming (DDP)
Similar to LQR, but can handle nonlinear dynamics and non-quadratic cost functions. Linearizes the dynamics and solves the LQR problem iteratively.
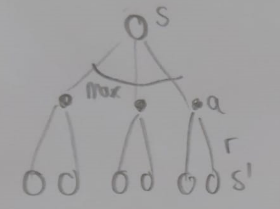
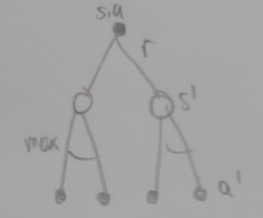
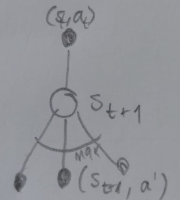
Backup Diagrams
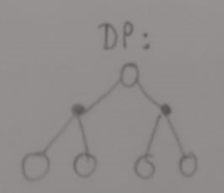


Bellman Equation for V:
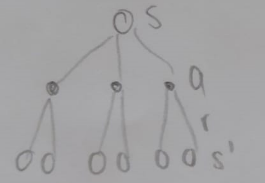
Bellman Equation for Q:
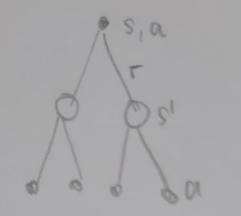
For Bellman Optimality Equation for V:
For Bellman Optimality Equation for Q:
Q-Learning:
Bayesian Methods
Bayesian methods provide a probabilistic framework for modeling uncertainty in Reinforcement Learning. They can be used for model learning, state estimation, and decision-making under uncertainty.
Satz von Bayes
Or with two states and measurement:
You can calculate the updated after taking an action with the same formula as .
Bayesian Inference
Instead of producing just a single “best estimate” of parameters, Bayesian inference updates probability distributions over them.
Bayesian Model Inference
Bayesian Model Inference can be used to find the model that fits the data the best:
It has two steps: Model Fitting and Model Comparison. In Model fitting, we find the parameters that explain the data best for each model. In Model comparison, we choose the model that fits the data best with its optimal parameters.
Fitting:
Comparison:
Bayesian Information Criterion BIC
The Bayesian Information Criterion (BIC) is a criterion for model selection among a finite set of models. It is based on the likelihood function and includes a penalty term for the number of parameters in the model.
Inverse Reinforcement Learning
In inverse reinforcement learning (IRL), the goal is to infer the underlying reward function that an expert is optimizing, given observations of the expert's behavior.
Feature Expectations
The feature expectations of a policy are the expected discounted sum of feature vectors when following that policy:
Max Margin Formula
We try to find weights so that the reward of the expert policy is better than the reward of any other policy by a margin, using slack variables for expert suboptimality:
Apprenticeship Learning
Try to match feature expectations:
Does not require the expert to be optimal. Reward ambiguity is not a problem because the feature expectations are matched directly.
Function Approximation
Function approximation is used in Reinforcement Learning to estimate value functions or policies when the state or action space is large or continuous. It allows generalization from seen states to unseen states.
Radial Basis Function Definition
Piecewise Linear RBF
Comments
Feel free to leave your opinion or questions in the comment section below.