Developing a Statistical Application
Design, implementation, and evaluation of a comprehensive, user-friendly, and secure statistical tool with an integrated code editor as a client-server application
Analyzing study data through statistical methods is a demanding and complex process where mistakes can have serious real-world consequences. Typically, data analysis is performed either using dedicated statistical applications or by writing code. Each approach has its own strengths and limitations, resulting in a fragmented landscape of available tools. As part of my bachelor’s thesis, I developed a statistics app that combines both approaches: simplifying and accelerating statistical analysis while reducing errors to enhance the reliability and safety of research outcomes.
Developing the Statistical Application
The resulting prototype already supports complete statistical analysis of arbitrary study data, making it a fully functional and independent statistical application. It is intended to be integrated into a larger application planned within the research group, which will also support the planning and execution of studies in addition to data analysis. With this in mind, the various components of the statistical application needed to be carefully planned and technically implemented with foresight. To execute user-written code and carry out statistical computations during data analysis, Jupyter Notebooks were used, enabling compatibility with existing tools. However, Project Jupyter alone was not sufficient to fulfill all the requirements and desired benefits defined in this thesis. Therefore, a custom client-server application was developed, composed of several independently developed components that together form the statistical tool.
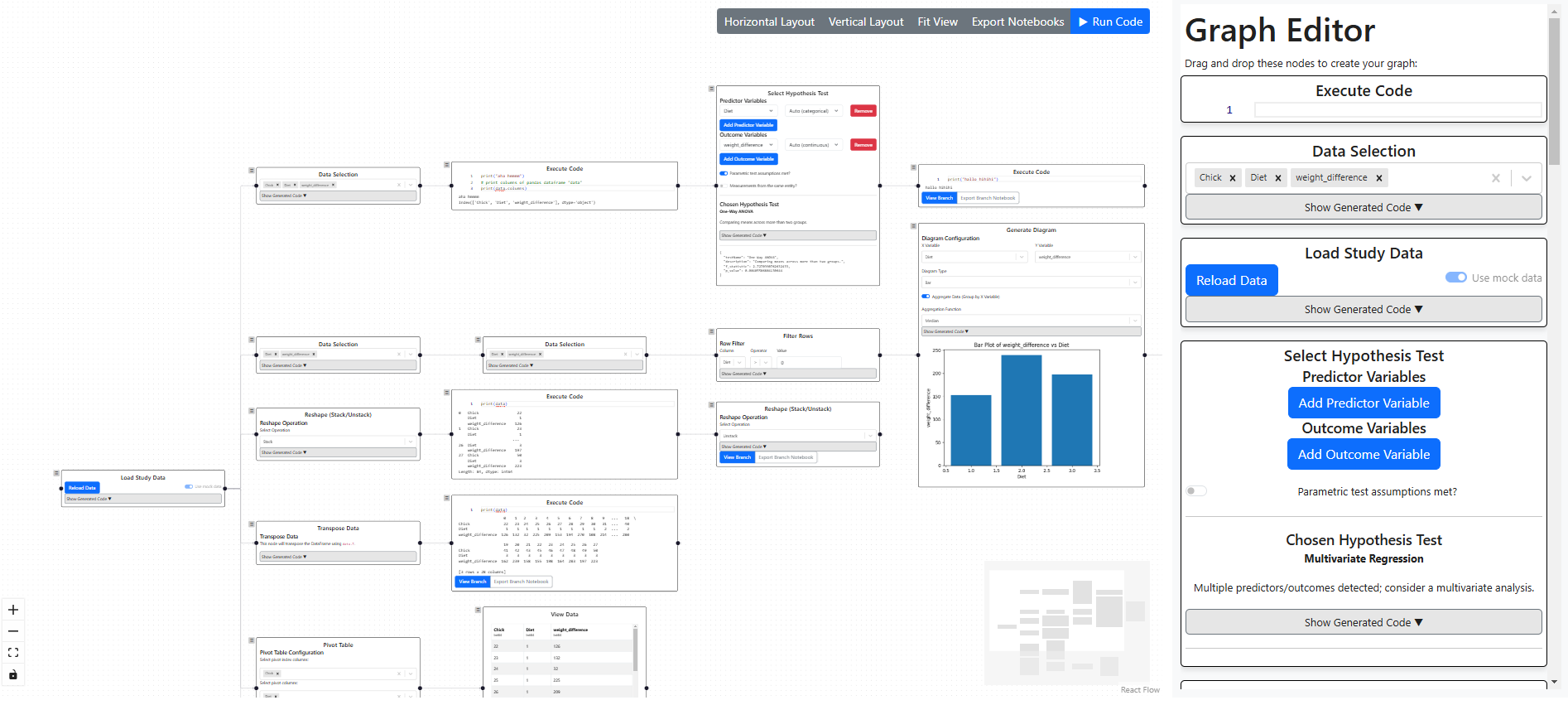
Graph-based editor used for conducting data analysis within the statistical applicationTechnical Architecture
The prototype is built as a client-server application. The client handles user interaction, while the application logic is delegated to various server-side components.
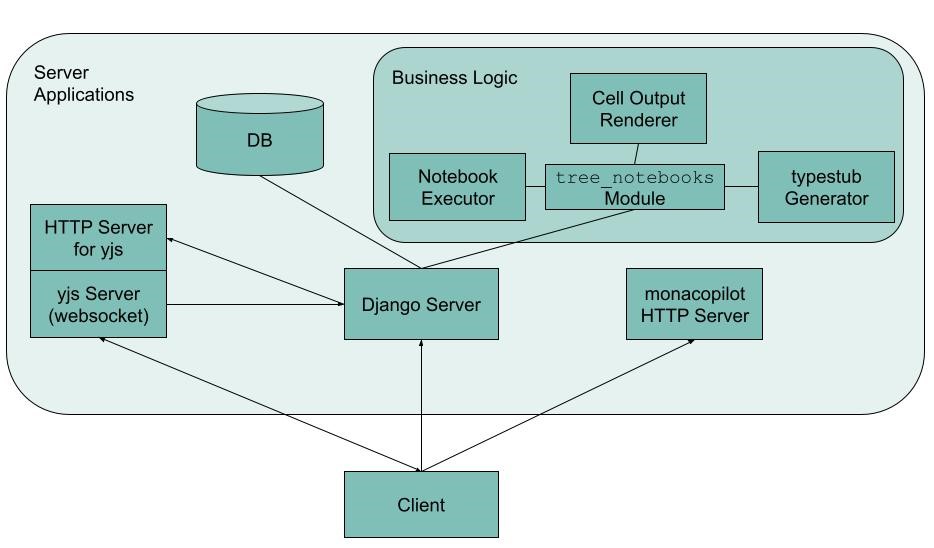 System architecture of the application
System architecture of the applicationThe most important components and features are outlined below.
Django Server
The client was implemented as a React application, providing the user interface. It communicates with server components via HTTP requests and WebSocket connections. At the core is a Django server responsible for storing all user data, analysis trees, and mock datasets. The server integrates a central Python module containing the application logic of the prototype (tree_notebooks.py, top right). This includes data types and operations related to the analysis trees, the execution of notebooks, rendering of outputs, and generation of additional Python type stubs for code cells. Since no existing standalone Jupyter-based tool could satisfy these needs, custom components based on Jupyter libraries were created.
YJS
To enable collaborative editing of code blocks, yjs was used. Multiple clients can work on the same code block simultaneously via WebSocket connections.
Monaco Editor
As the prototype supports writing code, a user-friendly UI component was necessary. The Monaco Editor, also used in Visual Studio Code, was chosen for this purpose.
When users choose to contribute their own code to the analysis, they are supported by AI-generated code completions. This feature is provided by an extension for Monaco Editor, which relies on a dedicated server to forward completion requests to a large language model (LLM).
 Code editor with AI-generated autocompletions
Code editor with AI-generated autocompletionsPyright Browser
The Language Server Protocol (LSP) support is provided by Pyright Browser, which runs entirely in the browser. Since the prototype is a fully web-based application, requiring only a browser with no additional software installations, this is a major advantage.
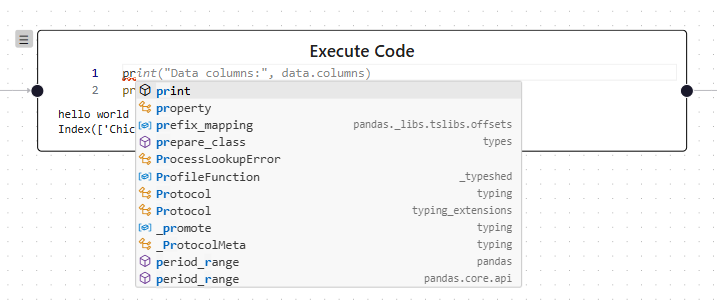 LSP support in the code editor
LSP support in the code editorType Stubs
Simply including type definitions from libraries wasn’t sufficient for an intuitive coding experience. The analysis tree consists of multiple code cells with hierarchical dependencies. As a result, previous cells’ type information must be preserved. This was solved by concatenating predecessor node code and generating stubs from it. A server component based on stubgen was implemented to generate type information from a given Python script and is used after code cell execution.
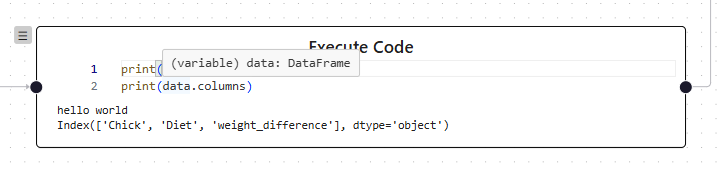 Type information of code cells within the analysis tree
Type information of code cells within the analysis treeNotebook Execution
Code cells are executed using nbclient, a library from the Jupyter ecosystem. It allows running Jupyter notebooks in any supported language with an appropriate kernel. Code cells from the analysis tree are inserted into a notebook and executed using nbclient.
Integration of Code and UI Elements
A core feature of the prototype is the seamless combination of code and graphical interface elements for statistical analysis. As shown in the application screenshot, this is realized through code-generating nodes in the analysis tree, which can be supplemented with nodes allowing arbitrary custom code. Each node is stored as part of the analysis tree in the database, maintaining its UI state and using that state to generate code dynamically.
Output Rendering
Code cell outputs are rendered using nbformat, another Jupyter library. A server component collects executed code cells and embeds them in a Jupyter notebook. The outputs are then rendered to HTML, cached, and returned to the client for display.
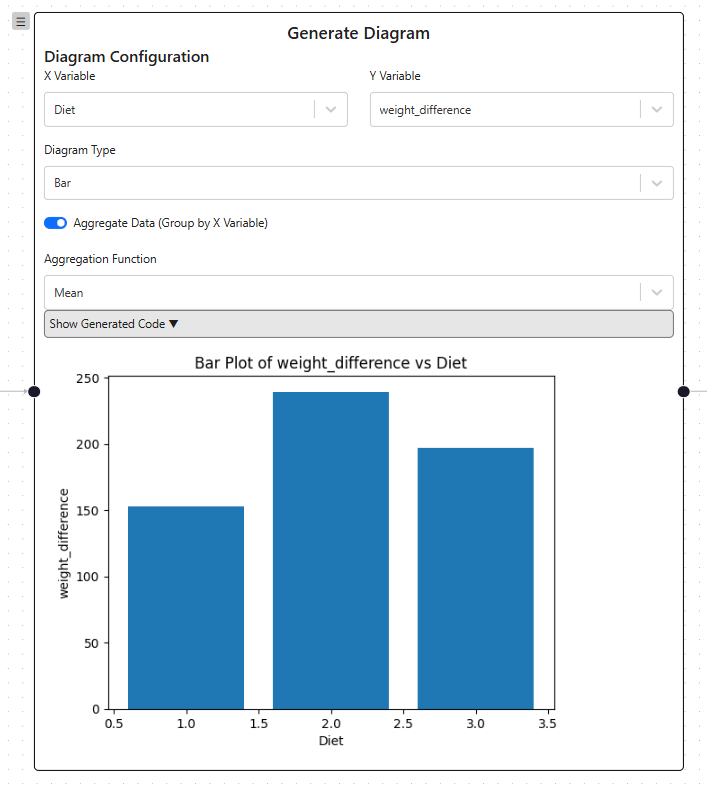 Even complex outputs like plots are rendered
Even complex outputs like plots are renderedDataset Mutations
To ensure that the interplay of code and UI remains intuitive and accurate, changes to the dataset must be reflected both in code generation and in UI components. As modifications in one node can affect all downstream branches, it’s not sufficient to rely on the dataset’s initial state. Therefore, node-specific dataset changes are stored and used to update the UI components of subsequent nodes accordingly.
Conclusion
Working on this project was not only an incredibly enjoyable experience - it also provided an opportunity to grow and demonstrate my software development skills. The final application was well received by the research group and will be a key component of the larger application currently in development.
Comments
Feel free to leave your opinion or questions in the comment section below.