Leihfahrrad Nachfrage mit Machine Learning vorhersagen
Wettbewerb des ML Clubs der Uni Bonn
Im Rahmen des ML Clubs der Uni Bonn haben wir an einem kleinen Wettbewerb teilgenommen, bei dem es darum ging, die Nachfrage nach Leihfahrrädern mittels Machine Learning vorherzusagen.
Aufgabe
Gegeben war ein Datensatz mit der Anzahl ausgeliehener Leihfahrräder pro Zeitpunkt, sowie einige weitere Informationen wie Wetterdaten und Feiertage. Die Aufgabe war es, ein Modell zu entwickeln, das auf einem ähnlichen Datensatz ohne die Anzahl der ausgeliehenen Fahrräder die Nachfrage möglichst korrekt vorhersagen kann. Die Qualität der Vorhersage wurde anhand des RMSE (Root Mean Squared Error) gemessen. Dieser gibt an, wie stark die Vorhersage von der tatsächlichen Nachfrage abweicht. Die Challenge wurde auf Kaggle ausgetragen, wo die eigenen Vorhersagen für einen weiteren Datensatz hochgeladen werden konnten.
Datenanalyse
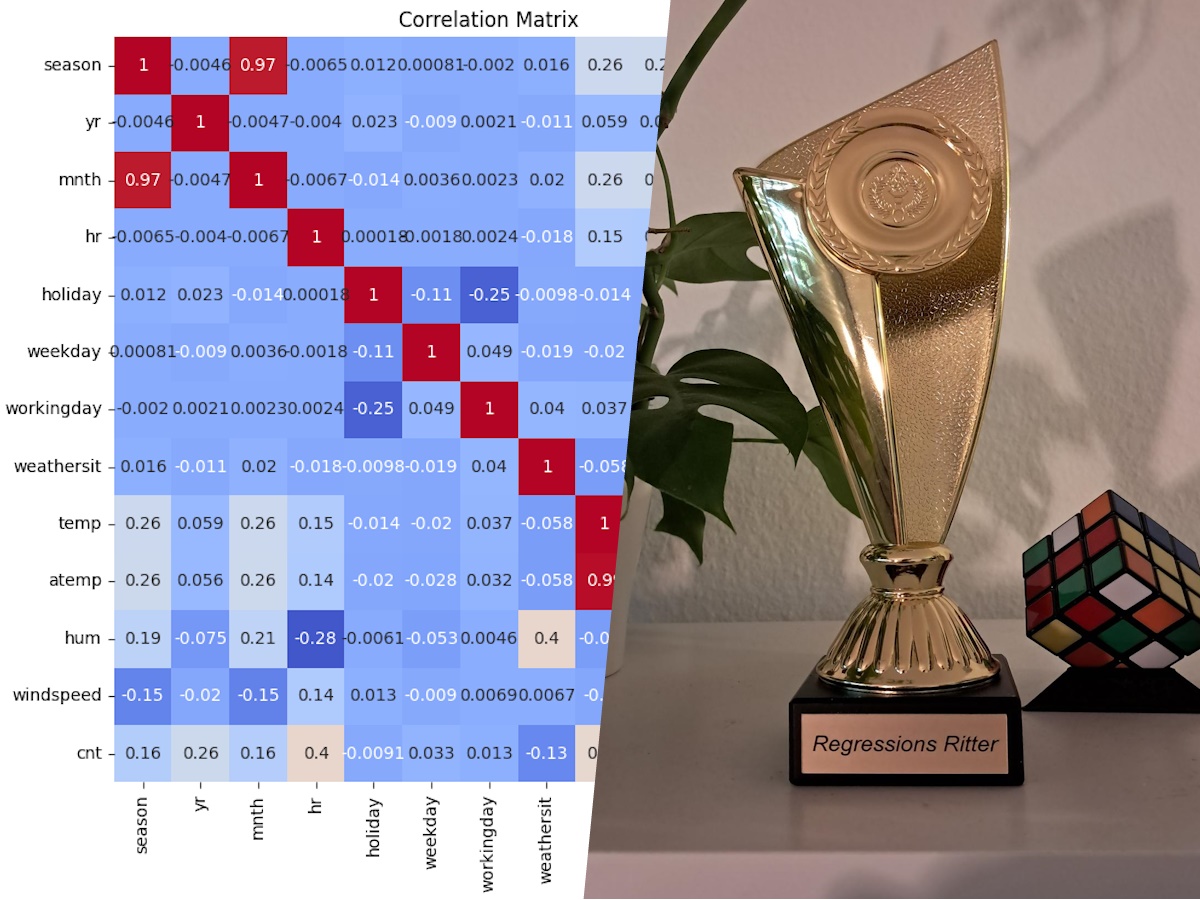
Bevor wir ein Modell entwickelt haben, haben wir uns die Daten genauer angeschaut, um zu entscheiden, welche Features wir verwenden wollen. Eine Korrelationsmatrix hat gezeigt, dass die Features temp (Temperatur) und atemp (gefühlte Temperatur), sowie season (Jahreszeit) und month (Monat) stark korreliert sind. Daher haben wir uns entschieden, die Features atemp und season nicht zu verwenden.
Modell
Für die Vorhersage der Nachfrage haben wir ein XGBoost-Regressionsmodell verwendet. Zunächst wurden die Daten bereinigt, indem Ausreißer in der Zielvariable cnt mit Hilfe der Interquartilsabstand-Methode (IQR) entfernt wurden. Anschließend wurden kategoriale Variablen per One-Hot-Encoding umgewandelt.
Das Modell wurde auf den logarithmierten Zielwerten trainiert, um die Verteilung zu glätten. Für die Hyperparameteroptimierung kam RandomizedSearchCVmit 5-fachem Cross-Validation zum Einsatz. Die wichtigsten Parameter wie max_depth, learning_rate,subsample und Regularisierungsparameter wurden dabei durchsucht.
Das beste Modell erzielte auf den Trainingsdaten einen RMSE von 31,53 und einen MAE von 19,24. Auf unseren eigenen Evaluationsdaten lag der RMSE bei 37,78 und der MAE bei 23,27. Zum Vergleich: Der Mittelwert der Zielvariable cnt beträgt etwa 190. Das Ergebnis ist nicht schlecht, aber auch nicht überragend. Da wir wenig Zeit hatten, haben wir uns entschieden, die Ergebnisse nicht weiter zu optimieren und die Challenge so einzureichen.
Die wichtigsten Features waren neben den Wetterdaten insbesondere die Uhrzeit, der Monat und der Wochentag.
Code
import xgboost as xgb
import numpy as np
from sklearn.model_selection import RandomizedSearchCV
from sklearn.metrics import mean_squared_error, mean_absolute_error
from os import path
import pandas as pd
from utils import one_hot_all
def load_data():
file = path.abspath(path.join("data", "train_data_bike.csv"))
df = pd.read_csv(file)
df = df.drop(columns=["atemp", "season", "dteday"])
df = one_hot_all(df)
print(df.columns.tolist())
# Use IQR to detect outliers in "cnt"
Q1 = df["cnt"].quantile(0.25)
Q3 = df["cnt"].quantile(0.75)
IQR = Q3 - Q1
outlier_mask = (df["cnt"] < (Q1 - 1.5 * IQR)) | (df["cnt"] > (Q3 + 1.5 * IQR))
outliers = df[outlier_mask]
print(f"Number of outliers: {outliers.shape[0]}")
outliers[["cnt"]]
df = df[~outlier_mask].reset_index(drop=True)
eval_df = df.sample(frac=0.25, random_state=42)
train_df = df.drop(eval_df.index)
eval_y = eval_df["cnt"]
train_y = train_df["cnt"]
eval_df = eval_df.drop(columns=["cnt"])
train_df = train_df.drop(columns=["cnt"])
return train_df, train_y, eval_df, eval_y
train_df, train_y, eval_df, eval_y = load_data()
param_dist = {
"n_estimators": [2000],
"max_depth": [5, 6, 7],
"learning_rate": [0.01, 0.02, 0.03],
"subsample": [0.4, 0.6, 0.8],
"colsample_bytree": [0.4, 0.6, 0.8],
"reg_alpha": [0.6, 0.8, 1],
"reg_lambda": [1, 5],
"min_child_weight": [3, 4],
"gamma": [0, 0.1],
"max_delta_step": [1, 2, 3],
}
xgb_model = xgb.XGBRegressor(random_state=42, tree_method="hist")
search = RandomizedSearchCV(
xgb_model,
param_distributions=param_dist,
n_iter=40,
cv=5,
scoring="neg_root_mean_squared_error",
n_jobs=-1,
random_state=42,
)
search.fit(train_df, np.log1p(train_y)) # still train on log-scale
best = search.best_estimator_
y_pred = np.expm1(best.predict(train_df)) # type: ignore
rmse = mean_squared_error(train_y, y_pred) ** 0.5
mae = mean_absolute_error(train_y, y_pred)
print(f"Tuned XGB → RMSE: {rmse:.2f}, MAE: {mae:.2f}")
print(search.best_params_)
y_pred_eval = np.expm1(best.predict(eval_df)) # type: ignore
rmse_eval = mean_squared_error(eval_y, y_pred_eval) ** 0.5
mae_eval = mean_absolute_error( eval_y, y_pred_eval)
print(f"Eval → RMSE: {rmse_eval:.2f}, MAE: {mae_eval:.2f}")Ergebnisse
Unser Modell erzielte auf den finalen Evaluationsdaten der Challenge einen RMSE von 56,897, was uns tatsächlich den ersten Platz einbrachte.

Kommentare
Noch Fragen?