
Quantencomputing Grundlagen
Zusammenfassung der Quantenvorlesung
The most important mathematical foundations are summarized in the following cheat sheet:
Cheat Sheet - Mathematical Foundations of Quantum Computing
Standard Qubit States
- |0⟩ =
- |1⟩ =
-
Inner product
-
Outer product examples:
Shortcut to calculating outer Products
Note that if you read the ket-bra as a binary number (e.g. as 2), the binary number corresponds to the index in the matrix where the 1 is. All others are 0.
Shortcut to calculating inner Products
Note that if the 2 numbers in the ket-bra are equal, the inner product returns 1, otherwise 0
Bra-ket (Inner Products)
| Expression | Description |
|---|---|
| Bracket | bra (horizontal) - ket |
Polar Basis States
Pauli Matrices
- X:
- Y:
- Z:
Pauli Matrices as outer Products
- X:
- Y:
- Z:
Hermitian Transpose
For , .
Transpose Matrix and complex conjugate its elements:
Effects on the Basis States
Effects of the Pauli Matrices and the Hadamard gate on the basis states and polar basis states
| Gate | Effect on |0⟩ | Effect on |1⟩ | Effect on |+⟩ | Effect on |−⟩ |
|---|---|---|---|---|
| X | |1⟩ | |0⟩ | |+⟩ | -|-⟩ |
| Y | i|1⟩ | -i|0⟩ | -i|−⟩ | i|+⟩ |
| Z | +|0⟩ | -|1⟩ | |-⟩ | |+⟩ |
| H | |+⟩ | |−⟩ | |0⟩ | |1⟩ |
Kronecker Product
- Associativity
- Distributivity
- Non-commutativity
- Mixed product property:
- Transpose and complex conjugate distribution:
Hadamard Gate
(For higher dimensions: , etc.)
Also,
and
Vector Space Axioms
- Commutativity of addition
- Associativity of addition
- Neutral element (existence of a zero vector)
- Inverse elements (existence of additive inverses)
- Distributivity (over vector addition and scalar multiplication)
- Scalar associativity (compatibility of scalar multiplication)
- Unity of scalar multiplication (existence of multiplicative identity)
Key Matrix Definitions
-
Hermitian:
- Hermitian matrices have real diagonal entries.
- Eigenvalues of a Hermitian matrix are real.
-
Normal:
-
Unitary:
- Eigenvalues have absolute value 1.
- has absolute value 1.
Useful Facts
-
Trace() = sum of eigenvalues.
-
Det() = product of eigenvalues.
-
Rank() = maximum number of linearly independent rows (or columns).
-
Exponential of a matrix:
- Log of a matrix (for suitably defined ):
and
Series expansions (for scalar ):
y-intercepts:
Symmetry:
Roots:
Relation to :
Idempotent and Projection
-
Idempotent: .
- Every idempotent matrix is a projection matrix (and vice versa).
- Eigenvalues of an idempotent matrix are 0 or 1.
- if is idempotent.
- If and are idempotent, then is idempotent only if .
- If and are idempotent, then is idempotent only if .
- idempotent, if A idempotent
-
Projection matrix :
- is idempotent
- Satisfies .
Involutory Matrices
- Involutory: .
- Eigenvalues are .
- .
- is idempotent is idempotent.
- is idempotent is idempotent.
- Powers of alternate between and .
- involutory only involutory if
Permutation Matrices
- Permutation matrix :
- Square, entries in .
- Exactly one "1" in each row and column, others 0.
- Sums of each row and each column are 1.
- Orthogonal, unitary, and invertible.
- If you multiply a permutation matrix by itself often enough, you eventually get the identity.
- Product of two permutation matrices is another permutation matrix.
Eigenvectors and Eigenvalues
- For matrix , an eigenvector and eigenvalue satisfy
- For a Hermitian , is real.
- For a Hermitian Matrix, its Eigenvectors are orthogonal
- For a unitary , .
- For an idempotent , .
- For an involutory , .
Permutation Matrices
- Permutation matrix :
- Square, entries in .
- Exactly one "1" in each row and column, others 0.
- Sums of each row and each column are 1.
- Orthogonal, unitary, and invertible.
- If you multiply a permutation matrix by itself often enough, you eventually get the identity.
- Product of two permutation matrices is another permutation matrix.
More or less relevant linear algebra concepts
Eigenvectors and Eigenvalues
- For matrix , an eigenvector and eigenvalue satisfy
Determinant of a Matrix
For a 2x2 Matrix
For a 2x2 matrix
the determinant is given by:
Using Cofactor Expansion
For an matrix, the determinant can be calculated using cofactor expansion along any row or column. For example, expanding along the first row:
where is the submatrix obtained by removing the first row and -th column of .
For example, for a 3x3 matrix
the determinant is given by:
Properties of Determinants
- Multiplicative Property:
- Transpose:
- Inverse: If is invertible,
- Determinant of Identity Matrix:
- Row Operations:
- Swapping two rows multiplies the determinant by .
- Multiplying a row by a scalar multiplies the determinant by .
- Adding a multiple of one row to another row does not change the determinant.
Kernel, Image, and Related Concepts
Kernel (Null Space)
The kernel (or null space) of a matrix , denoted as or , is the set of all vectors such that . In other words, it is the set of solutions to the homogeneous equation .
Image (Column Space)
The image (or column space) of a matrix , denoted as or , is the set of all vectors that can be expressed as for some vector . It is the span of the columns of .
Rank
The rank of a matrix , denoted as , is the dimension of the image (column space) of . It represents the maximum number of linearly independent columns of .
Nullity
The nullity of a matrix , denoted as , is the dimension of the kernel (null space) of . It represents the number of linearly independent solutions to the homogeneous equation .
Rank-Nullity Theorem
The rank-nullity theorem states that for any matrix :
where is the number of columns of .



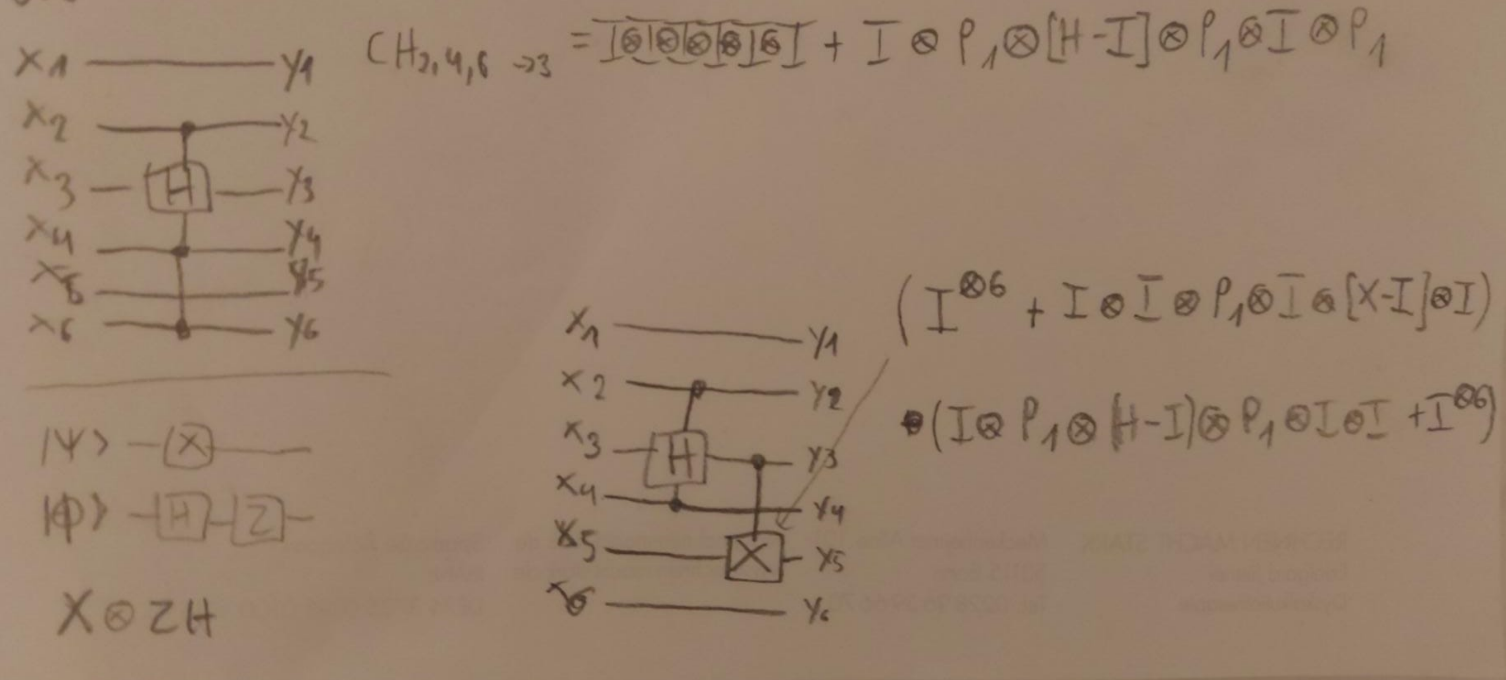
Worksheets
General Bit Manipulation
- Calculate required bits for a binary number:
- Convert a decimal number to binary:
- Convert a decimal number to binary grey code: *
- Bitshift right by 1: equivalent to dividing by 2
Boolean Fourier Transform
Every pseudo-boolean function can be represented as a polynomial in the form of a sum of products of boolean variables:
Example:
TODO task 1.6
Hadamard
Hadamard Matrix Definition
- Hadamard Matrix:
- For higher dimensions:
Hadamard Transform
Because the Hadamard matrix is unitary, it is involutory. If we want to solve for , we can calculate it directly:
Fourier
Fourier Matrix Definition
- Fourier Matrix:
- is a primitive -th root of unity
Fourier Transform
Because the Fourier matrix is unitary, it is involutory. If we want to solve for , we can calculate it directly:
TODO task 2.3 b)
Bool-Möbius Transform
Sierpinski Matrix
- Sierpinski Matrix:
Bool-Möbius Transform
Because , the Sierpinski matrix is involutory. If we want to solve for , we can calculate it directly:
Yet another Feature Transform
Compared to our original
we now have
Recursive definition:
Pauli Matrices
- The Pauli Matrices are unitary and involutory.
- They can easily be written as linear combinations of outer products:
- Because they are unitary, their Eigenvalues are of norm 1. Because they are Hermitian, their Eigenvalues are real. Therefore, the Eigenvalues of the Pauli Matrices are .
- Because they are Hermitian, their Eigenvectors are orthogonal.
- Their Eigenvectors are:
- : and
- : and
- : and
- : and
Matrix Exponential
Therefore,
Linear Combinations of Pauli Matrices
Every matrix can be written as a linear combination of the Pauli Matrices.
This is because we can write the standard basis as a linear combination of the Pauli Matrices:
Example
The Matrix
Beam Splitter
Wiederholt sich beim Quadrieren.
Bivariate Functions as 2x2 Matrices
Every bivariate function can be represented as a 2x2 matrix.
With and , we can write the function as
| x | y | Expression for xT M y |
|---|---|---|
| 0 | 0 | a |
| 1 | 0 | a + c |
| 0 | 1 | a + b |
| 1 | 1 | a + b + c + d |
| Coefficient | Expression |
|---|---|
| a | f(0,0) |
| b | f(0,1) - a |
| c | f(1,0) - a |
| d | f(1,1) - a - b - c |
3D Vectors as Matrices
Every 3D vector can be represented as a matrix.
Note the following:
And for square matrices:
Therefore, the inner product of 2 real vectors is symmetric
Born Rule
the spatial component of the wave function of a 1D particle trapped in a 1D well is given by
elsewhere.
Inner Product is 0 when orthogonal, i.e., when two different eigenvectors are multiplied, the result is 0.
If we have two identical eigenvectors:
4th roots of unity
Rotations in the complex plane
To rotate a complex number by an angle, we multiply it by
What is ?
Phase Gate
It is the generator of:
Quaternions
Quaternions are a non-commutative extension of complex numbers.
Quaternions as Matrices
The matrices for (i), (j), and (k) are given as:
The product (ijk) gives:
Finally, multiplying further:
This aligns with (ijk = -1).
TODO 4.9
Vector Logic
Example
Given a matrix
multiplying it with, say, gives you the first column of the matrix, which is .
You can also write C as:
because the kronecker product is linear.
Bilinearity of the Kronecker Product
We start with:
Distributing the terms:
Which simplifies to:
Tensor Products and the Born Rule
If we have two states and that obey the Born rule, then the tensor product of these states also obeys the Born rule.
Kommentare
Noch Fragen?