Entwicklung einer Statistikanwendung
Planung, Implementierung und Evaluation eines umfangreichen, benutzerfreundlichen und sicheren Statistikprogramms mit integriertem Code Editor als Client-Server-Anwendung
Die Auswertung von Studiendaten mittels statistischer Analysen ist ein anspruchsvoller und komplexer Prozess, bei dem Fehler erhebliche Auswirkungen in der realen Welt haben können. Die Analyse der Daten wird meist in einer Statistikanwendung oder durch das Schreiben von Code durchgeführt. Beide Möglichkeiten bieten Vor- und Nachteile und sorgen für eine heterogene Landschaft an verfügbaren Hilfsmitteln. Im Rahmen meiner Bachelorarbeit habe ich eine Statistikanwendung entwickelt, der beide Ansätze vereint, um statistische Analysen einfacher, schneller und weniger fehleranfällig zu gestalten und so die Sicherheit und Verlässlichkeit von Forschungsergebnissen zu verbessern.
Entwicklung der Statistikanwendung
Der entstandene Prototyp erlaubt bereits die Durchführung einer vollständigen statistischen Analyse auf beliebigen Studiendaten und ist somit eine eigenständige, funktionsfähige Statistikanwendung. Diese soll in einer innerhalb der Arbeitsgruppe geplanten Gesamtanwendung weiterverwendet werden, welche, zusätzlich zur Auswertung von Studien, auch die Planung und Durchführung dieser ermöglichen soll. Im Hinblick darauf mussten die einzelnen Komponenten der Statistikanwendung vorausschauend geplant und auf technischer Ebene sinnvoll implementiert werden. Um den von den NutzerInnen verfassten Code auszuführen und die statistischen Berechnungen bei der Datenanalyse durchzuführen, wurden Jupyter Notebooks verwendet, wodurch eine Kompatibilität zu bestehenden Anwendungen entsteht. Die Verwendung von Project Jupyter allein reichte jedoch noch nicht aus, um einen Prototypen zu entwickeln, welcher die für diese Arbeit festgelegten Anforderungen an die Statistikanwendung erfüllt und die gewünschten Vorteile erreicht. Daher wurde eine eigenständige Client-Server-Anwendung entwickelt, welche aus verschiedenen, selbst entwickelten Komponenten besteht und diese zu einer Statistikanwendung verbindet.
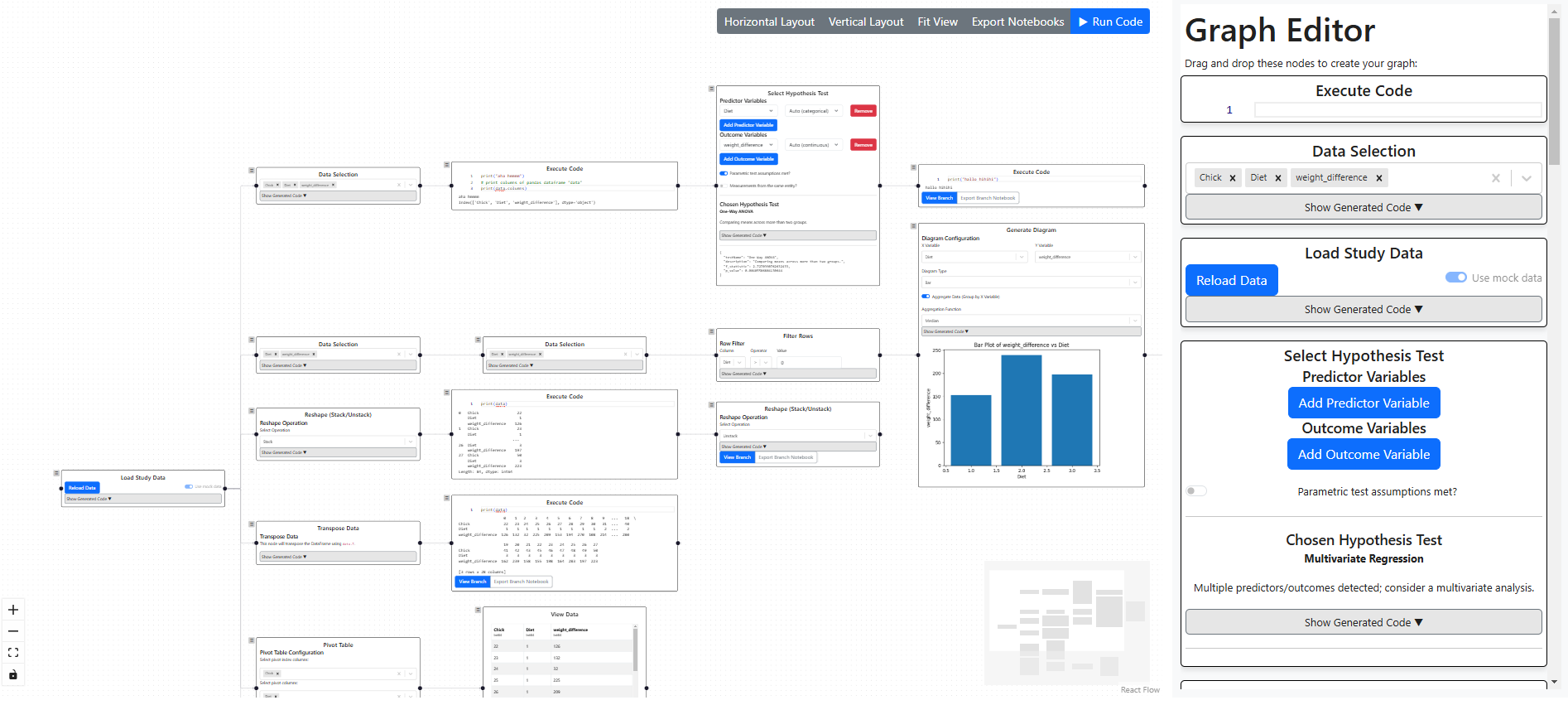
Graph-basierter Editor für die Durchführung der Datenanalyse in der entstandenen StatistikanwendungTechnischer Aufbau der Anwendung
Der Prototyp wurde als Client-Server-Anwendung entwickelt. Der Client ist dabei vorrangig für die Benutzerinteraktion zuständig, während die Anwendungslogik in verschiedene Serverkomponenten ausgelagert wurde.
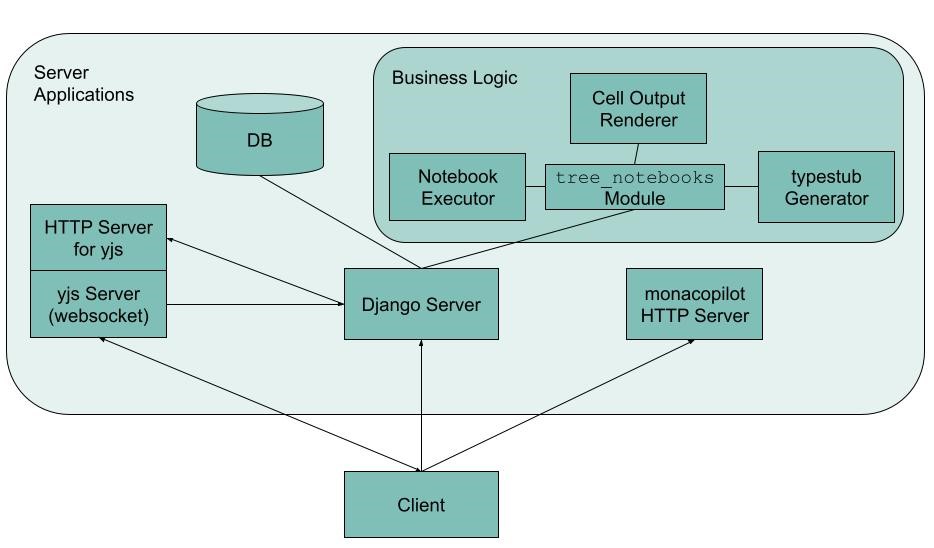 Systemarchitektur der Anwendung
Systemarchitektur der AnwendungDie wichtigsten Komponenten und Features sollen im Folgenden kurz vorgestellt werden.
Django-Server
Der Client wurde als React-Anwendung entwickelt und definiert die Benutzeroberfläche. Der Client kommuniziert über HTTP-Anfragen und Websocket-Verbindungen mit den Server-Komponenten. Der zentrale Server ist für die Speicherung aller Nutzerdaten, Analysebäume und Mock-Daten zuständig. Es handelt sich um einen Django-Server. Der Django-Server nutzt ein zentrales Python-Modul, welches die Anwendungslogik des Prototypen enthält (tree_notebooks.py, oben rechts). Zur Anwendungslogik gehören alle Datentypen und Operationen in Bezug auf die Analysebäume, sowie auch das Ausführen der Notebooks, das Rendern der entstehenden Outputs und das Generieren von zusätzlichen Python Typestubs für die Code-Zellen der Bäume. Da keine Standalone-Anwendung aus dem Jupyter Universum verwendet wurde, welche die Codezellen ausführt und rendert, mussten dafür eigene Komponenten auf Basis von bestehenden Jupyter-Libraries entwickelt werden.
YJS
Um kollaboratives Arbeiten an den Code-Blöcken zu ermöglichen, wurde yjs verwendet. Mehrere Clients können über eine Websocket-Verbindung an einem Code-Block arbeiten.
Monaco Editor
Da der Prototyp das Schreiben von Code ermöglichen soll, wird eine UI-Komponente benötigt, die dies auf nutzerfreundliche Art ermöglicht. Dazu wurde der Monaco Editor verwendet, welcher auch in Visual Studio Code verwendet wird.
Wenn sich der Nutzer entscheidet, eigenen Code in die Datenanalyse einzubringen, wird er von KI-generierten Autovervollständigungen unterstützt. Die dafür verwendete Erweiterung für den Monaco Editor benötigt einen zusätzlichen Server, der Anfragen zur Vervollständigung des Codes annimmt und an ein LLM weitergibt.
 Code Editor mit KI-generierten Autovervollständigungen
Code Editor mit KI-generierten AutovervollständigungenPyright Browser
Als LSP-Server wurde Pyright Browser verwendet. Dieser läuft im Gegensatz zu klassischen LSP-Servern im Browser, in dem der Client aufgerufen wird. Da der Prototyp vollständig als Webanwendung entwickelt wurde und zur Verwendung der Statistikanwendung nur der Aufruf einer Website ohne die Installation von zusätzlichen Tools nötig sein soll, ist dies von großem Vorteil.
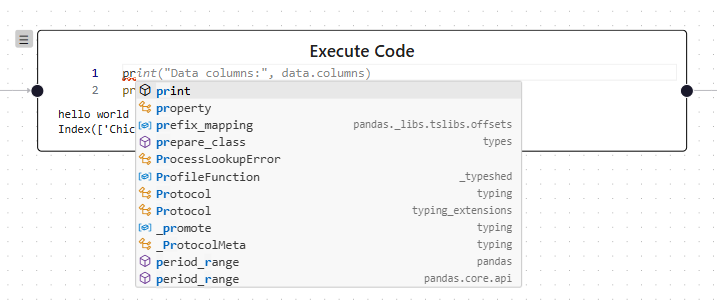 LSP-Unterstützung im Code Editor
LSP-Unterstützung im Code EditorType Stubs
Für die intuitive Bedienung des Code Editors war das Hinzufügen der Typinformationen der verfügbaren Bibliotheken nicht ausreichend. Dies liegt daran, dass der Analysebaum mehrere Code-Zellen enthält, die unterschiedliche Bezüge zueinander haben, da sie baumförmig angeordnet sind und die Typinformationen der vorherigen Zellen benötigt werden. Dafür kann der Code der Vorgänger-Knoten konkateniert werden und auf die am Ende verfügbaren Typinformationen hin untersucht werden. Entsprechend wurde eine Server-Komponente basierend auf stubgen entwickelt, die Typinformationen zu einem gegebenen Python-Skript generiert. Diese wird nach der Ausführung der Code-Zellen verwendet.
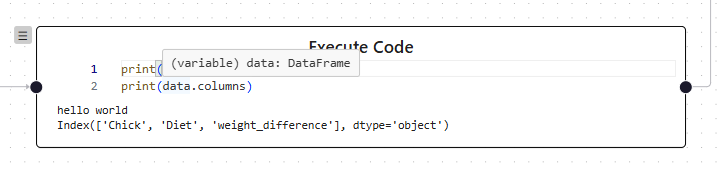 Typinformationen der Code-Zellen im Analysebaum
Typinformationen der Code-Zellen im AnalysebaumAusführung der Notebooks
Die Ausführung der Code-Zellen erfolgt über eine Bibliothek aus dem Jupyter Universum, „nbclient“. nbclient ermöglicht das Ausführen von Jupyter Notebooks in beliebigen Sprachen, solange ein passender Kernel für diese Sprache zur Verfügung steht. Die auszuführenden Code-Zellen aus dem Analysebaum werden in ein Jupyter Notebook eingefügt und mit nbclient ausgeführt.
Zusammenspiel von Code und UI-Elementen
Ein zentraler Aspekt des Prototypen ist die Kombination der Verwendung von Code und Benutzeroberflächenelementen zur Durchführung der statistischen Analyse. Wie aus dem gezeigten Screenshot der Anwendung ersichtlich wird, wurde dies mithilfe von Code-generierenden Knoten im Analysebaum umgesetzt, welche durch solche ergänzt werden können, die das Einfügen von beliebigem, eigenen Code erlauben. Die einzelnen Knoten werden als Teil des Analysebaums in der Datenbank gespeichert, enthalten den aktuellen Zustand der Benutzeroberfläche und können anhand dessen Code generieren.
Output Rendering
Um die Outputs der Code-Zellen zu rendern, wurde die Bibliothek „nbformat“ aus dem Jupyter Universum verwendet. Es wurde eine Serverkomponente entwickelt, die alle Code-Zellen, deren Output gerendert werden soll, nach der Ausführung in ein Jupyter-Notebook einfügt, diese mithilfe von nbformat als HTML-Elemente rendert, als Text speichert, cached und zurück an den Client sendet, welcher diese dann anzeigt.
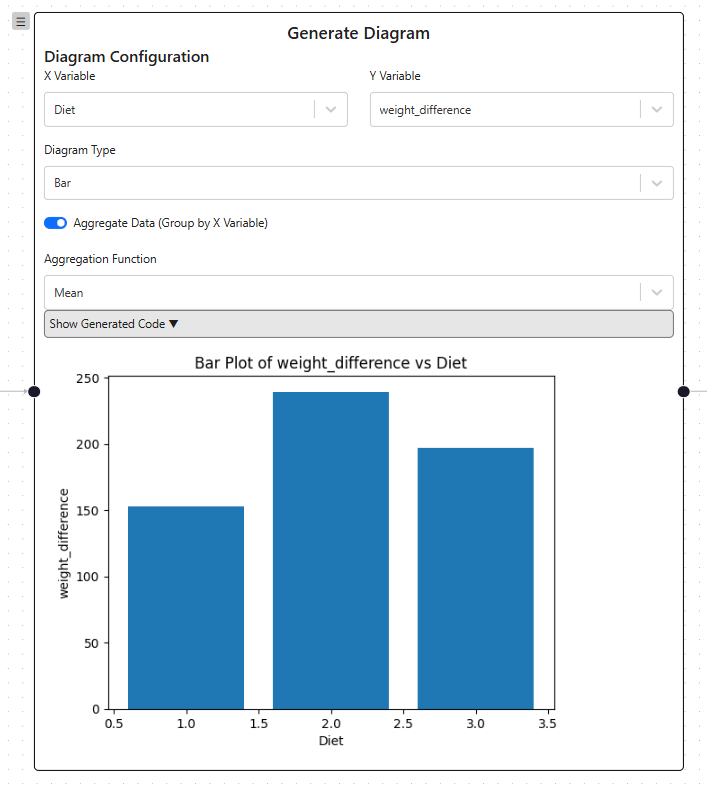 Auch komplexe Outputs wie Diagramme werden gerendert
Auch komplexe Outputs wie Diagramme werden gerendertVeränderung des Datensatzes
Um die Kombination von Code und UI auf intuitive und korrekte Weise umzusetzen, muss der Zustand des Datensatzes, auf welchem bei der statistischen Analyse gearbeitet wird, mit in die Generierung des Codes einfließen und sich in den UI-Elementen der Knoten widerspiegeln. Da Änderungen am Datensatz in einem Knoten Auswirkungen auf alle davon ausgehenden Äste haben, reicht es nicht, den Zustand des Datensatzes ganz zu Beginn zu verwenden, um die UI-Elemente in den Knoten zu erzeugen. Dieses enge Zusammenspiel von Code und UI ist nicht gegeben, sondern musste zusätzlich implementiert werden, indem Veränderungen am Datensatz in den Knoten gespeichert werden und zur Generierung der UI-Elemente nachfolgender Knoten verändert werden.
Fazit
Die Arbeit an diesem Projekt hat mir nicht nur großen Spaß gemacht, sondern mir auch die Möglichkeit gegeben, meine Fähigkeiten in der Softwareentwicklung weiterzuentwickeln und unter Beweis zu stellen. Die entstandene Anwendung kam in der Arbeitsgruppe sehr gut an, wird daher auch in Zukunft weiterverwendet und soll ein wichtiger Bestandteil der Gesamtanwendung werden.
Kommentare
Noch Fragen?